In this tutorial, we’re going to create our first custom webpage in django. The main goal of this article for you to understand the whole flow of information in django website like if someone asks for specific url then how do we route them into the correct places and ultimately give them back some HTML.
So before starting this article I am assuming that you’ve started the local server using python3 manage.py runserver command in project directory.
We’ve seen that whenever we create a project and run it in browser then django’s default page shows up.
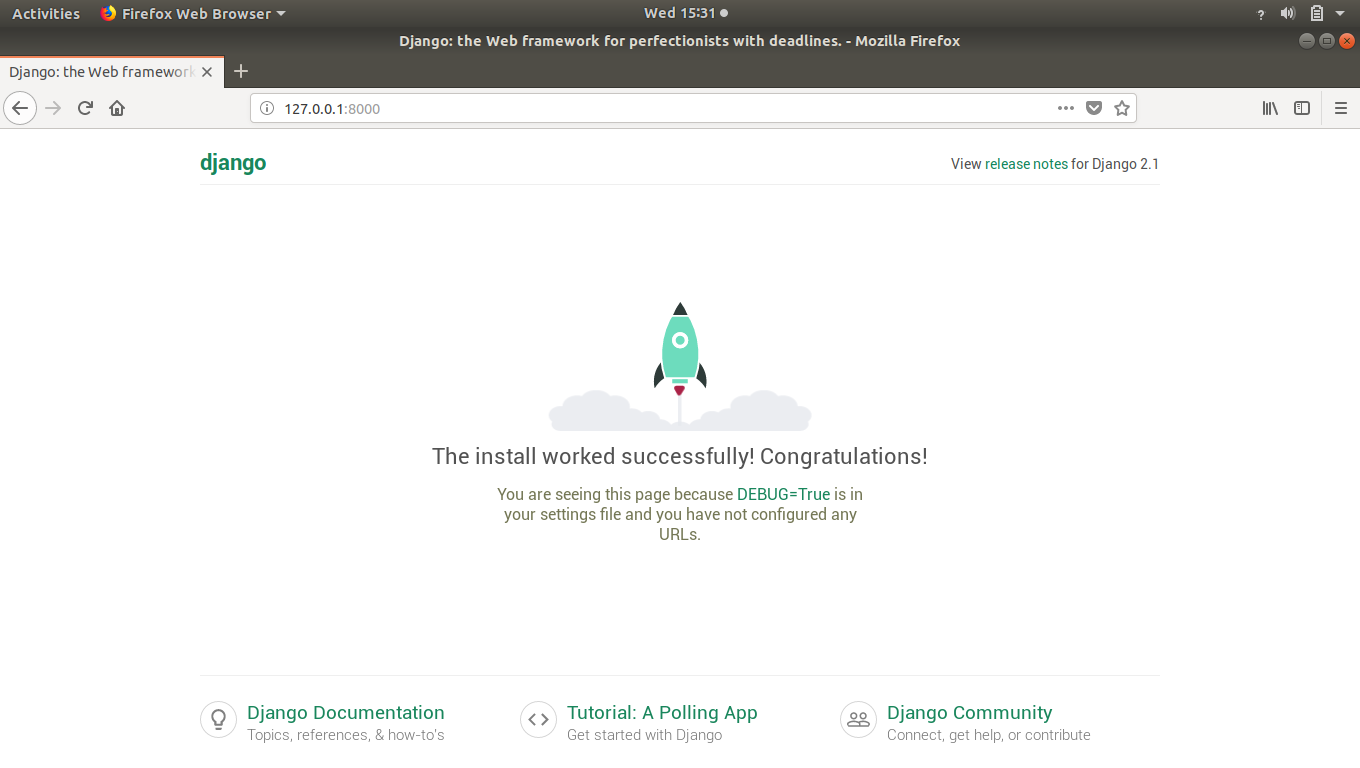
That’s isn’t our creation right.
So let’s see how to create our own webpage in django.
In previous articles, we’ve seen that anytime someone is looking for a URL on our website it comes to this “urls.py”.
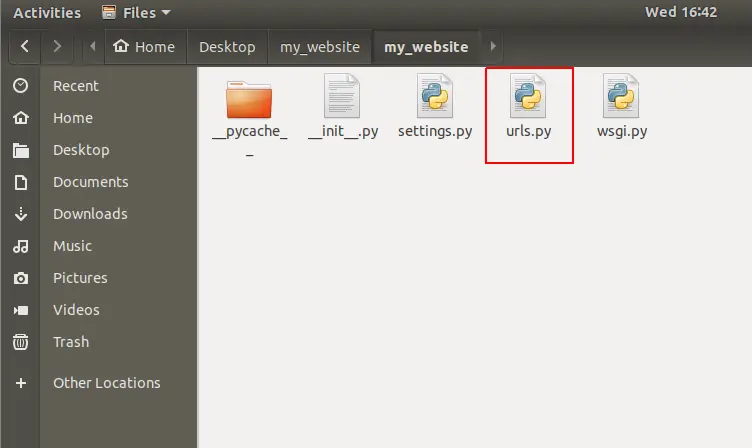
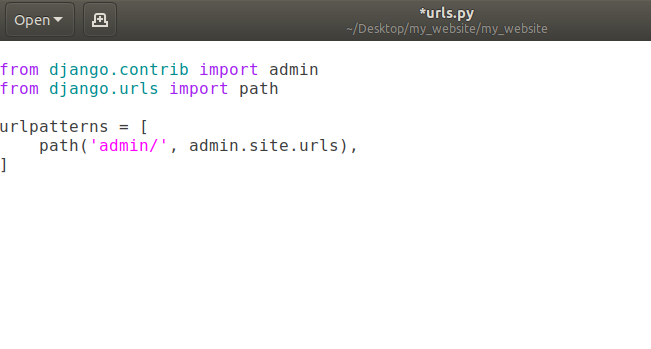
Currently we’ve path of admin/ in the list urlpatterns. That means when user goes to our website (currently = http://127.0.0.1:8000/) and add a /admin in the url, user will be redirected to admin page of our django website.
Note: That domain-name/admin (currently domain-name is http://127.0.0.1:8000/) is going to help us eventually work with the database but we don’t really need to worry about that right now.
How to Change URL of Existing Webpages
Let’s say we want to change the URL for our admin page then we can modify our urls.py file like this:
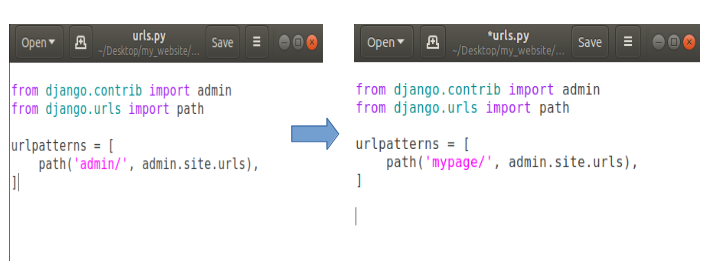
Now open your web browser and open domain-name/admin (http://127.0.0.1:8000/admin)
The result will be an error showing that page can not be found or something like this because we have changed the address of our admin page. So our new address is doman-name/mypage (http://127.0.0.1:8000/mypage). Open this address and the result will be:
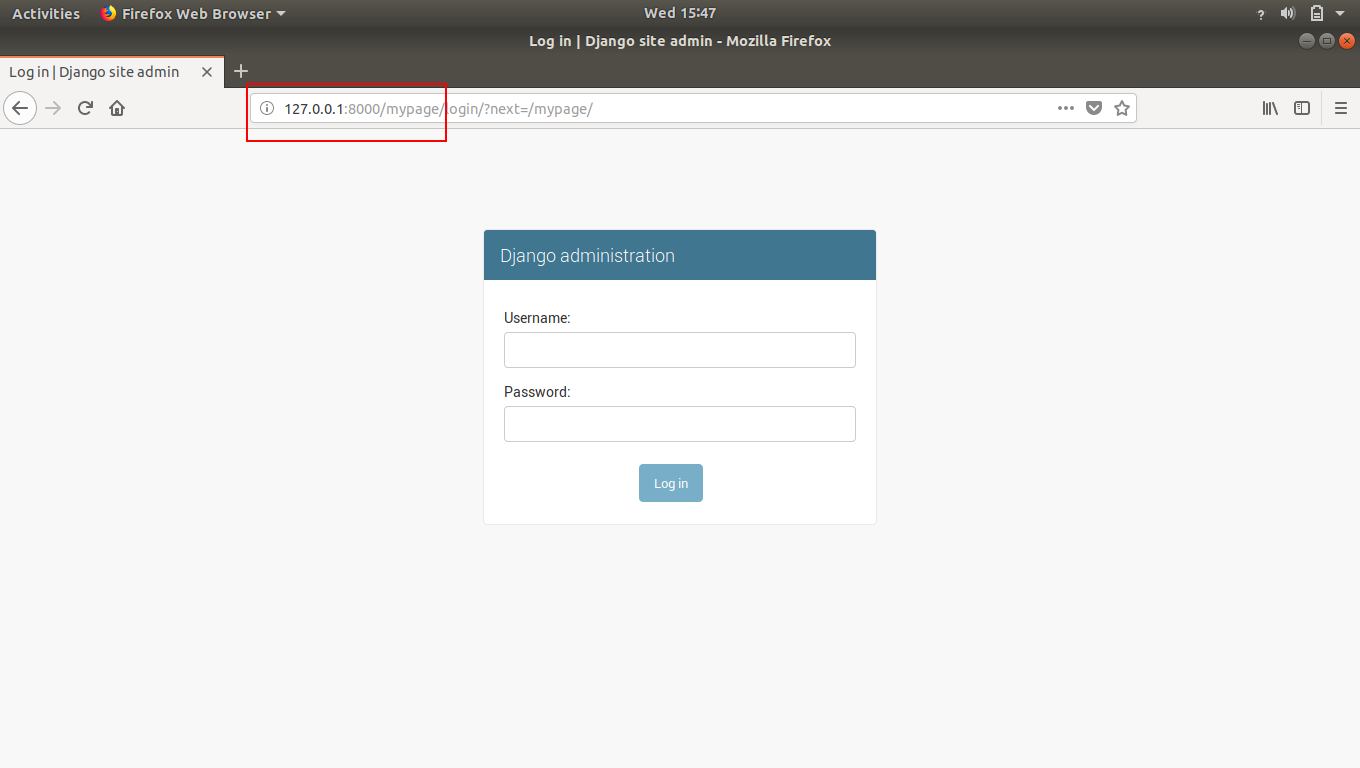
That how we can change any existing web-page’s URL.
Note: In django, anytime you make a change to a file, it is going to auto-reload the server for you. So we don’t have to manually go back to stop and start the server to pick-up the new changes.
Creating Our Own Custom Webpage in Django
Now our task is to make our own custom webpage so let’s do it.
Firstly, we don’t need that admin page so delete that path entirely.
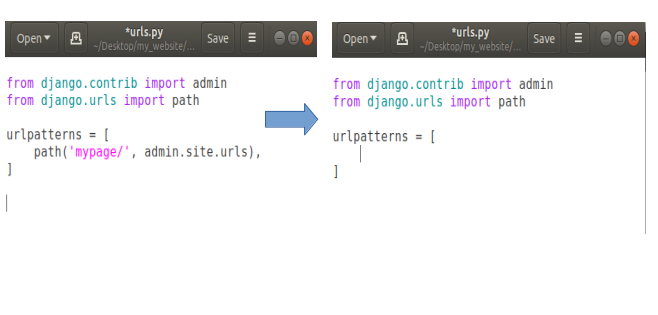
In fact we can delete the first line about admin in our urls.py as we don’t need admin anymore.
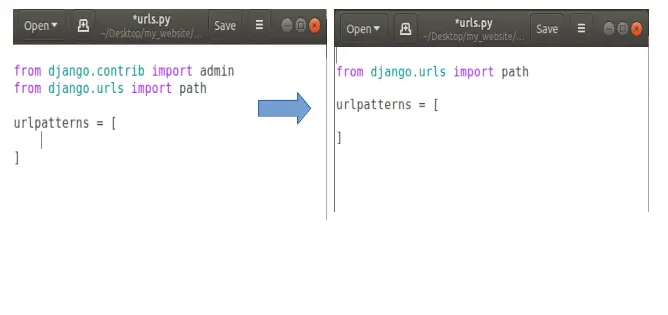
Now let’s say we’re going to add a path for our own page. Let’s say homepage. So when someone comes to the homepage of our website then we’ll show them our own custom homepage instead of that default django template page.
To do this, open your urls.py and add a new path. Basically if someone comes to our homepage means they don’t need to any thing extra our domain-name (http://127.0.0.1:8000/), so we’ll put a empty string in path, like this:
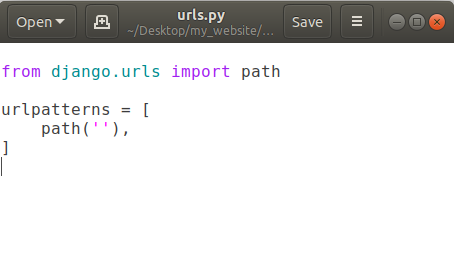
Now in path put a comma after the empty string and after comma (,) we’ll add another thing that will show that when someone comes to our homepage then where we want to send the user to.
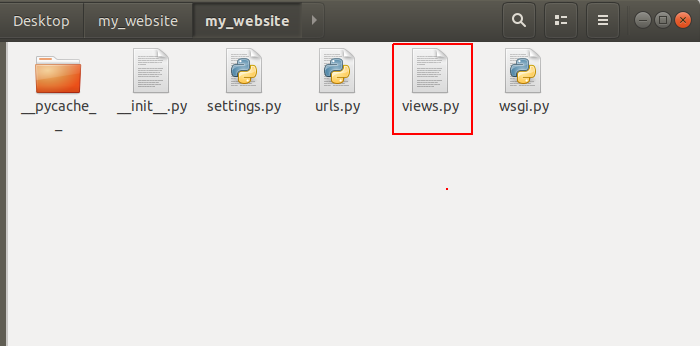
Here we have to create a new file called views.py which essentially allows us to send back some information.
So we’ll create a new file in same directory where our urls.py exists. Now we’ve a new file called views.py here:
To use views.py into our urls.py, we’ve to import views.py in urls.py file. So open urls.py and add the following line:
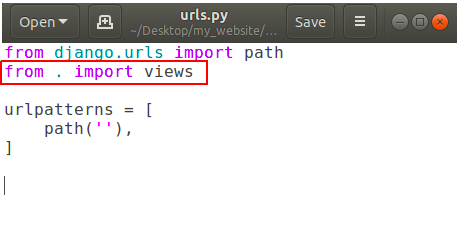
In above picture dot (.) means current directory.
Now add a function to call in our path into urls.py.
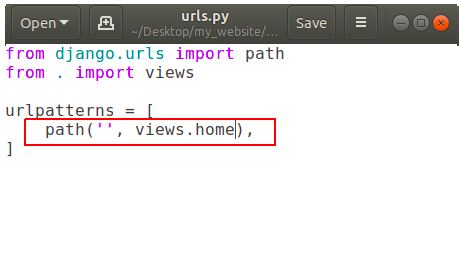
It is showing that if someone goes to our homepage then call the function ‘home’ which is located in our views.py, but we don’t have any function called home in our views.py yet.
So let’s create it. Open views.py and add a new function called home.
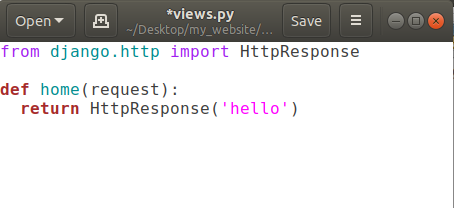
Here we’ve to pass request parameter in home function, anytime someone is coming for URL of our website it sends this request object which basically says that what’s the url they looking for and some more advanced information like some cookies and what browser they are using. So that type of information comes through this request object.
Then we’re returning something back to the user using return keyword But we can’t return a simple string back from our function, we’ve to give back an HTTP response. So in order to do that we’ve to use function HttpResponse(string) and to use HttpsResponse(string) we’ve to import some package using
from django.http import HttpResponse
Now save this file and reload your website. The output will be:
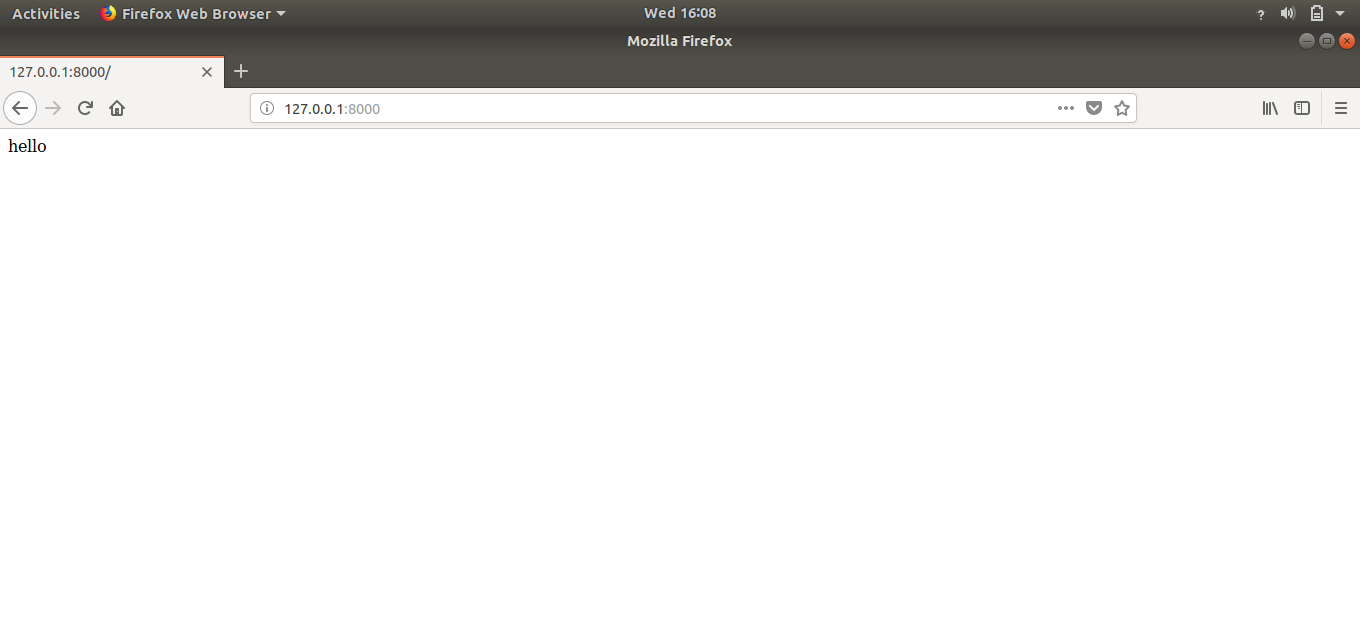
Congratulations, we have our own creation on our homepage.
Flow of Information in Our Django Website
If somebody is opening our website’s homepage (http://127.0.0.1:8000/) then they will be redirected to our urls.py file. Urls.py check the entered url by the user. As there is no extra string after the domain-name in above example. So in urlpatterns, it will check for the empty string and as we’ve one path having an empty string, it will be redirected to the function written in path with empty string, that is views.home in our case. Now that home function in views.py is finally returning some HttpsResponse that is ‘hello’. So user have the information that he/she requested for.
That’s how the flow of information works in django.
Creating Multiple Webpages in Django
As we make one custom webpage, we can also add some more web-pages having unique addresses assigned to them.
Open urls.py and add a new path like:
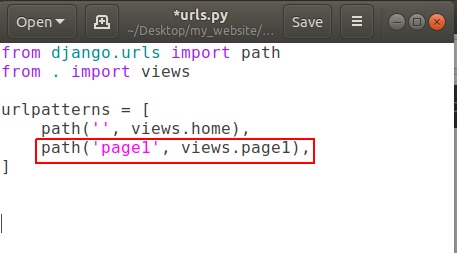
and open your views.py and create a new function for page1 .
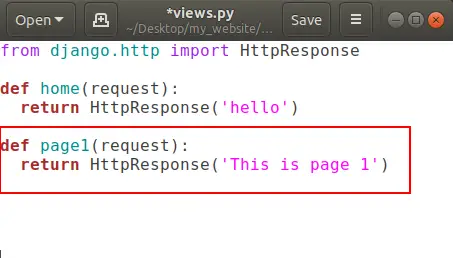
That’s all.
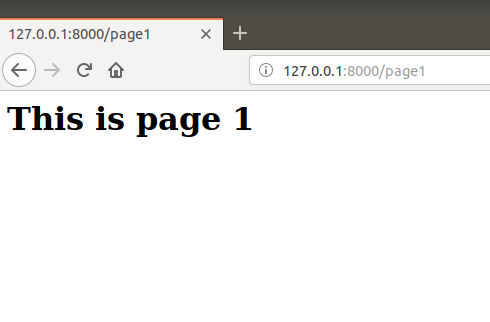
Now go to domain-name/page1 (http://127.0.0.1:8000/page1) and here is your page1:
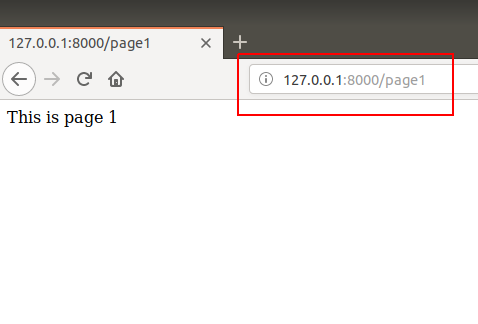
That’s how we can create multiple pages in our website.
Actually that string we’re returning is some HTML so we can also use HTML tags in it like:
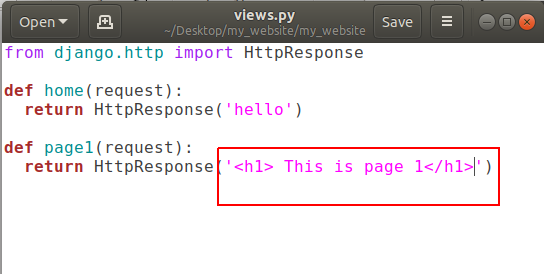
and refresh http://127.0.0.1:8000/page1
Conclusion
After reading and using this tutorial you’ll learn how to add a custom URL to any page, adding custom webpage in django website, creating multiple web-pages in django and the most important thing that is flow of information in django website.
Comment down below if you have any queries.
The post Django Custom Webpage appeared first on The Crazy Programmer.
from The Crazy Programmer https://www.thecrazyprogrammer.com/2018/10/django-custom-webpage.html

 There’s a great new bunch of guidance just published representing Best Practices for creating .NET Libraries. Best of all, it was shepherded by JSON.NET’s James Newton-King. Who better to help explain the best way to build and publish a .NET library than the author of the world’s most popular open source .NET library?
There’s a great new bunch of guidance just published representing Best Practices for creating .NET Libraries. Best of all, it was shepherded by JSON.NET’s James Newton-King. Who better to help explain the best way to build and publish a .NET library than the author of the world’s most popular open source .NET library? You likely know that open source .NET Core is cross platform and it’s super easy to do “Hello World” and start writing some code.
You likely know that open source .NET Core is cross platform and it’s super easy to do “Hello World” and start writing some code.